
Beyond software: The rise of Large Language Models and the ultimate abstraction layer
In this article, we explore the potential impact of LLMs to create new abstraction layers in several different domains of computer science.

An abstraction layer is a fundamental concept in computer science, allowing people to create increasingly complex technology while keeping a manageable cognitive load. Most of the major developments in computing, ever since the creation of transistors, involved the creation of new abstraction layers.
Transistors and integrated circuits abstracted away the physical complexity of electrons inside a vacuum tube. Microprocessors incorporated the functionality of an entire central processing unit into a single chip, enabling complex computing capabilities. Operating systems created an abstraction layer between hardware and software, simplifying application development and resource management.
Abstraction layers also popped up in software development (from 1s and 0s all the way up to the no-code tools we use today), computer networks (from the internet’s predecessor ARPANET to modern-day APIs and Zapier), and how humans interact with computers (from punch cards to touching the screen of your iPhone to use a modern day app).
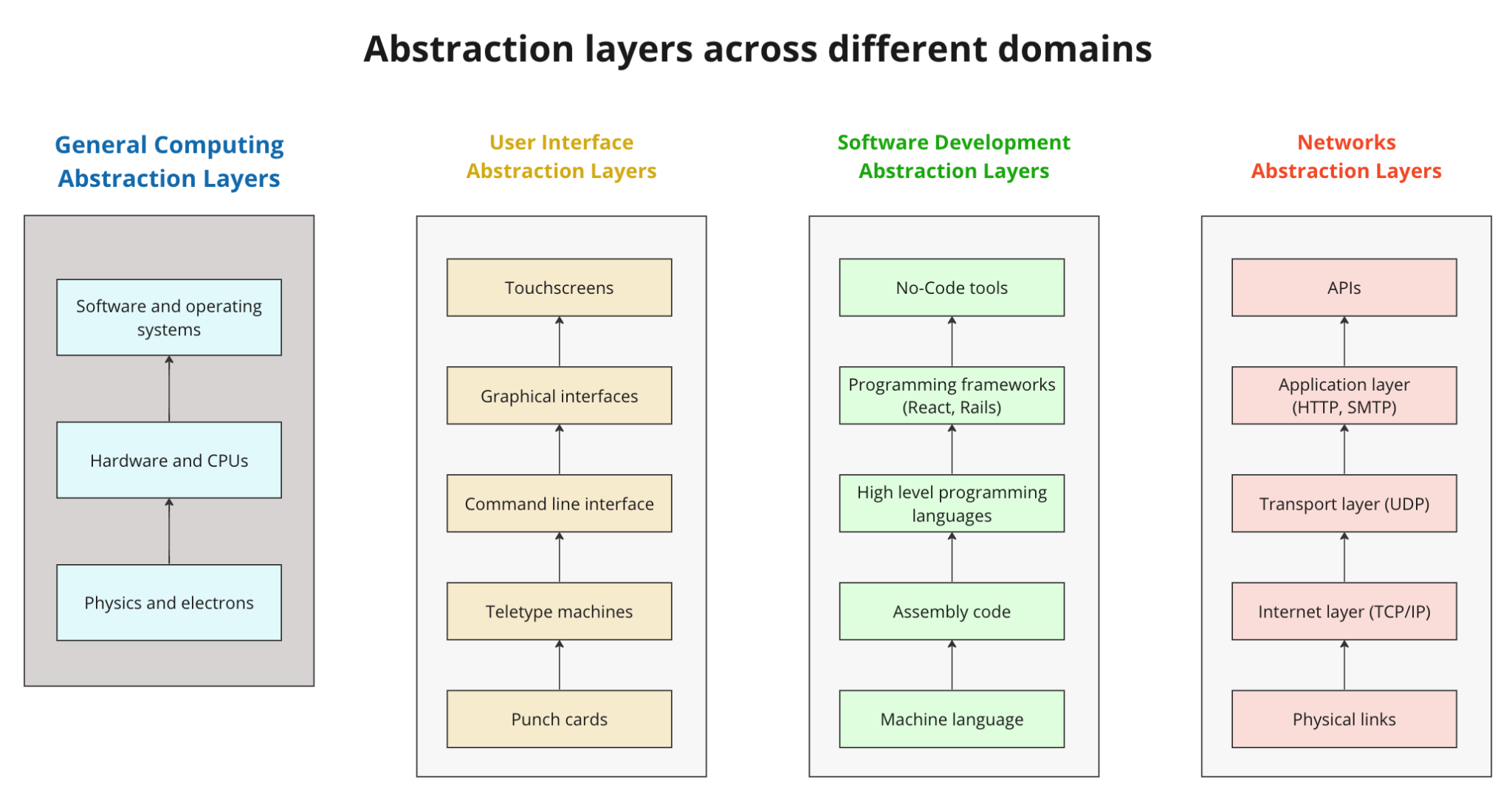
Each of these developments pushed the frontiers of what was possible to build, enabled people to build more quickly and, by lowering technical barriers, expanded the number of people who could build in the first place.
These developments, however, arose more or less independently. The rise of Large Language Models (“LLMs”, such as OpenAI's GPT-4, Google’s PaLM 2, and others) has the potential to be the first technology revolution to create a “multipurpose” abstraction layer, a single technology creating new abstraction layers not in one but in several of the domains above. To reimagine how we interact with computers, write code, connect computers to each other, and even how computers, well, compute.
This article explores the impact of LLMs as a potential new abstraction layer in each of the categories above.
User interface
While computers think in 1s and 0s, humans do not, so how we interact with each other has always been a challenge in getting the most out of them. People initially interacted with early computers through “punched cards” that exactly matched the binary code a machine would process. Then came command line interfaces (think of MS/DOS or Mac’s Terminal) and the graphical user interfaces that replaced them.
The release of the iPhone in 2007 and its touchscreen interface was arguably the latest major breakthrough in user interface. Of course we now have Siri and Alexa, but it is hard to make the case that these have represented a turning point in interacting with computers, as their ability to understand open-ended commands remains quite limited.
The release of the conversational interface of ChatGPT in November 2022 marked a new breakthrough in the history of user interfaces, and has the potential to redefine the human-machine interaction paradigm. For the first time, computers are able to actually “decode” natural language used by a human and process this input directly.
For now, processing it means answering questions, but it will soon mean performing real-world actions such as booking hotel reservations, taking part in brainstorming sessions, or simply ordering groceries in a more convenient way, marking a remarkable upgrade in how easily people can interact with computers.
Software development
Traditionally, software development involved a human breaking down a problem, devising a solution, and translating it into code. This process demanded technical knowledge and labor-intensive efforts from developers. The advent of LLMs is already reshaping this approach, offering groundbreaking improvements.
Developers can now describe to an LLM what a code should accomplish, by providing a high-level description of what should be built, and the model will generate the actual code by itself. This allows developers to shift their focus from the granular details of coding to expressing their intent or goals more naturally. With this capability, developers no longer need to spend time figuring out specific coding solutions themselves, as language models can autonomously propose solutions and generate the corresponding code.
The impacts of these advancements in software development productivity have been remarkable. For instance, a 57% reduction in time needed to complete tasks has been observed in this study by GitHub, allowing developers and teams to deliver projects more efficiently. At Lastro, the company where I serve as CEO, we’ve seen a remarkable increase in story points delivered per sprint due to the integration of GitHub Copilot into software development processes.
While these improvements are already significant, we expect an even brighter future. The rapid evolution of LLMs is likely to further enhance efficiency and capabilities, revolutionizing software development and pushing the boundaries of what we can create in the digital world.
Note: while the impacts of LLMs on user interfaces and software development are already relatively straightforward, the next two sections, on networks and hardware, are more of a long shot. Correspondingly, one can find them more interesting too.
Networks
As discussed in the User Interface section, LLMs allow computers to communicate with humans using natural language. This capability, however, isn’t limited to a human interface: these models can also be used to enable two computers (or two different applications) to communicate with each other using natural language as well.
Several experiments trying to do this popped up on the internet in the last few weeks, a personal favorite being Smallville, an experiment by researchers from Stanford University and Google who created a virtual village populated by 25 generative AI "agents", each with unique identities and goals. The agents interact with each other and their environment, exhibiting "believable individual and emergent social behaviors”.
This capability can be used to connect real-world applications as well. By leveraging natural language instead of the highly structured protocols of APIs, LLMs can pave the way for applications to communicate with each other in the same way humans interact with them, effectively creating a new abstraction layer for the network stack.
Imagine two friends who each equip their GPT-powered assistants with their travel preferences, then let these agents negotiate and coordinate a trip itinerary by talking to each other, without being restricted by a rigid API architecture; or an e-commerce application explaining details about its products and return policies to an automated personal shopping assistant.
At Lastro, we’re creating a real estate broker application that allows people to browse for properties, get personalized information, schedule visits, and so forth. The application uses different “agents” that communicate through natural language with the customer, with each other, and even with third parties, streamlining the entire process.
Whether this type of connectivity will be more efficient and reliable than current protocols remains to be seen, but the mere possibility of this happening is already something that would have amazed us not a long time ago.
Computation stack
While the previous sections explored the impacts of LLMs in specific domains, these models can have an even greater impact when we look at computation itself. Computers started evolving as transistors abstracted away the physical complexity of vacuum tubes and electrons, then operating systems abstracted away the whole hardware stack into software, and finally high-level programming languages made the process of writing software a lot easier.
Despite all these advancements, our computing paradigm remains a deterministic one. Writing an application in Python still performs the same operations as instructing a computer in assembly language. Theoretically, it could even be rewritten by combining an enormous amount of transistors in the right way.
That is why computers are awesome at processing data and at math tasks, but terrible at performing “probabilistic” tasks easily done by humans, such as communicating thoughts or deciding what actions to take under certainty. Planning a strategy, negotiating with a counterpart, or starting a company, for instance, are all inherently probabilistic endeavors.
LLMs can easily deal with uncertainty by generating a range of potential outcomes, and can represent, for the first time, a major shift from deterministic to probabilistic computing. They have been shown, for example, to have the ability to perform "Chain of Thought Reasoning", breaking down a goal into sub-tasks necessary for its completion and planning on how to perform them. It is as, after being trained on massive datasets of human knowledge, the models start to be capable of emulating human logic.
This can give birth to a new computation abstraction layer, one that would be created on top of traditional, deterministic software, and deal exclusively with probabilistic computing by means of language models and its extensions. In this case, the “locus of computation” moves from arithmetic operations performed at a CPU to the hidden value parameters of a large language model, whereas the importance of chip and software design gets replaced by a focus on model architectures and training, which become the central frontier for extending our computing potential.
Embracing probabilistic computing allows us to handle real-world complexity and perform tasks that were previously the exclusive domain of humans due to their inherent uncertainty and nuance.
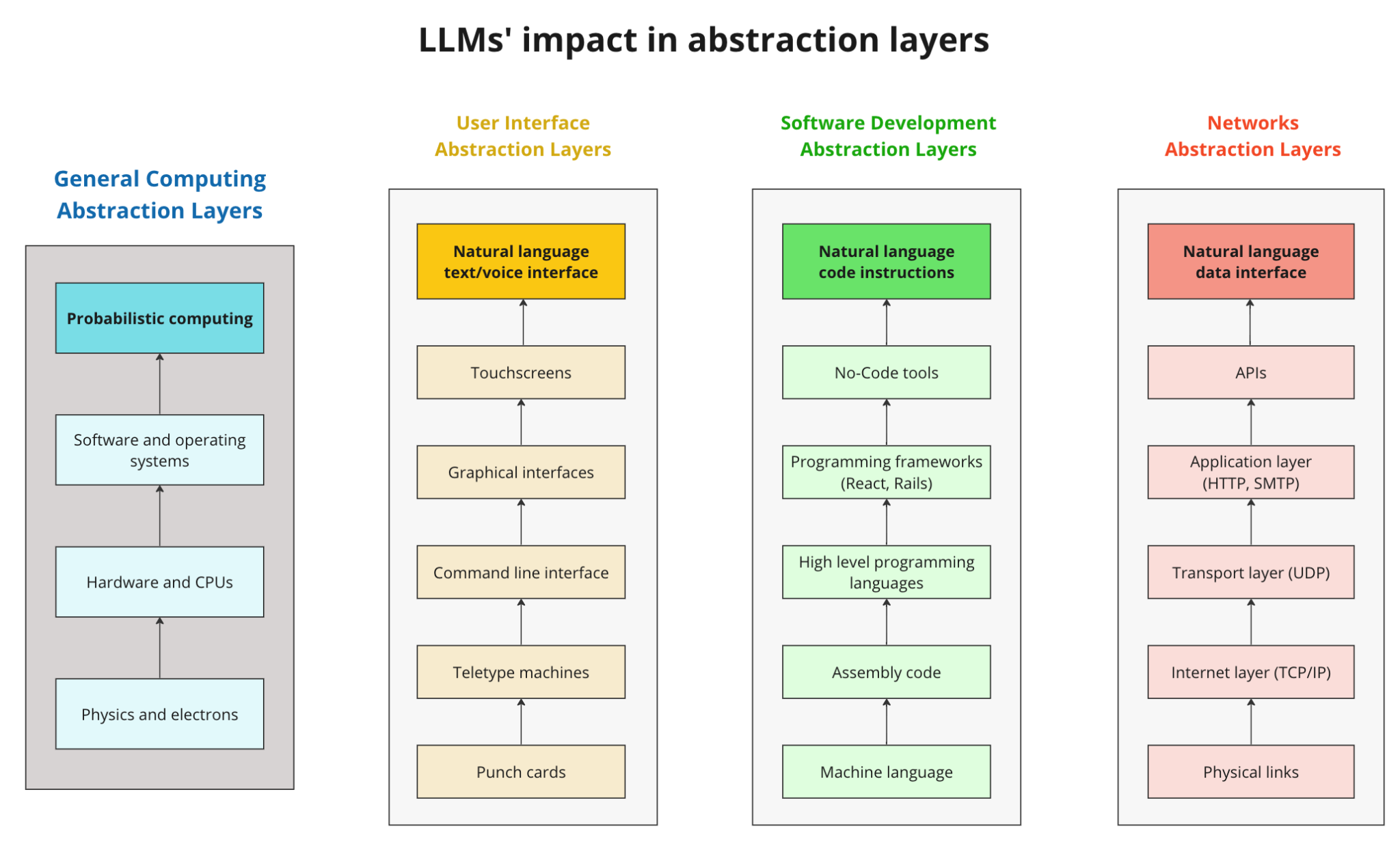
Each new abstraction layer in isolated categories brought major impacts on the whole technology industry. This is the first time, however, that a single breakthrough is capable of creating such an impact on so many different domains at once.
As we continue to explore the potential of LLMs, it becomes increasingly clear that these models have an incredible potential to redefine our relationship with technology and open up whole new possibilities for automation and intelligent decision-making. It could be not only about just creating new computational tools but also about redefining entirely what computation even means.